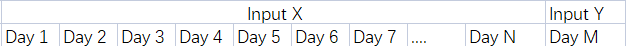1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
| import pandas as pd
import json
import arrow
from google.cloud import firestore
from google.cloud import storage
import os
import requests
import gcsfs
import json
import numpy as np
from sklearn.linear_model import LinearRegression
import schedule
import time
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]=os.path.abspath("./prediction-melb-8c16f470aeda.json")
os.environ["GCLOUD_PROJECT"]="prediction-melb"
storage_client = storage.Client()
db = firestore.Client()
buckets = list(storage_client.list_buckets())
bucket = storage_client.get_bucket("bomdata")
def isFileExistInBukect(file):
return storage.Blob(bucket=storage_client.bucket("bomdata"), name=file).exists(storage_client)
def uploadFileToBukect(filename):
blob = bucket.blob(filename)
blob.upload_from_filename(os.path.abspath(filename))
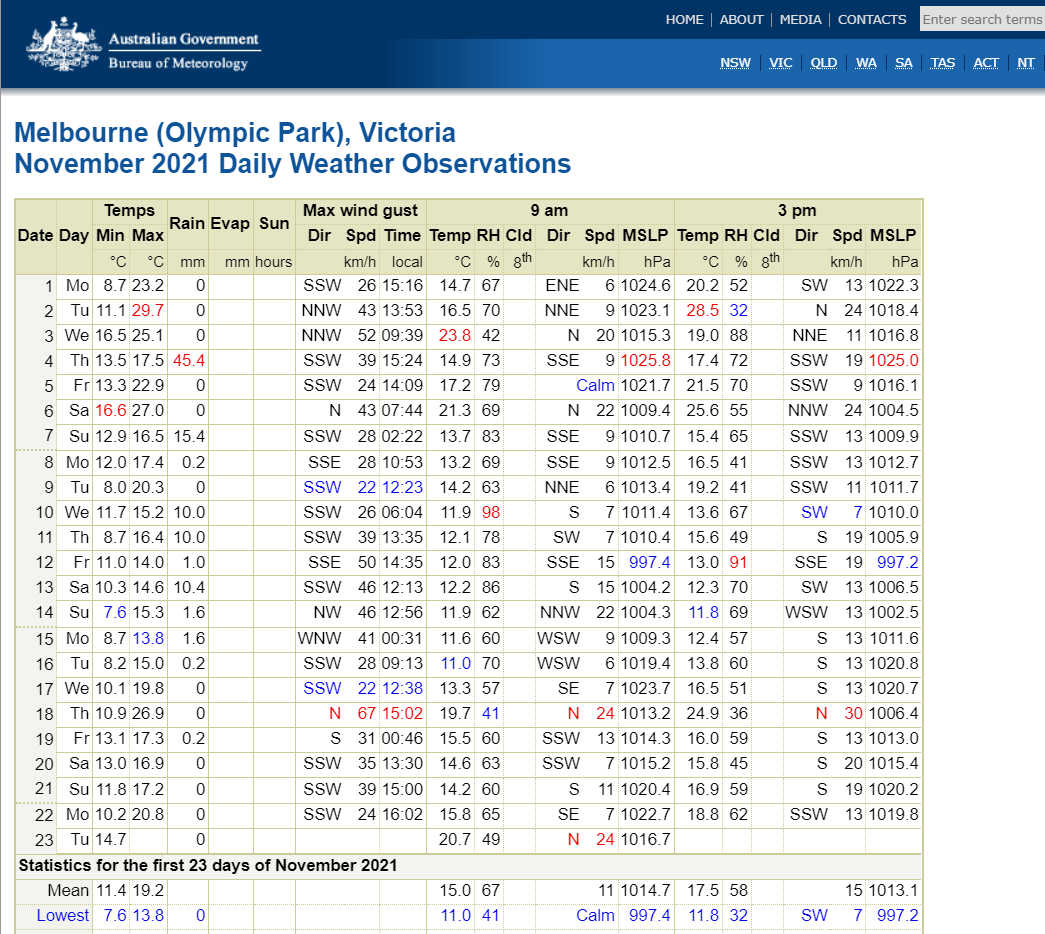
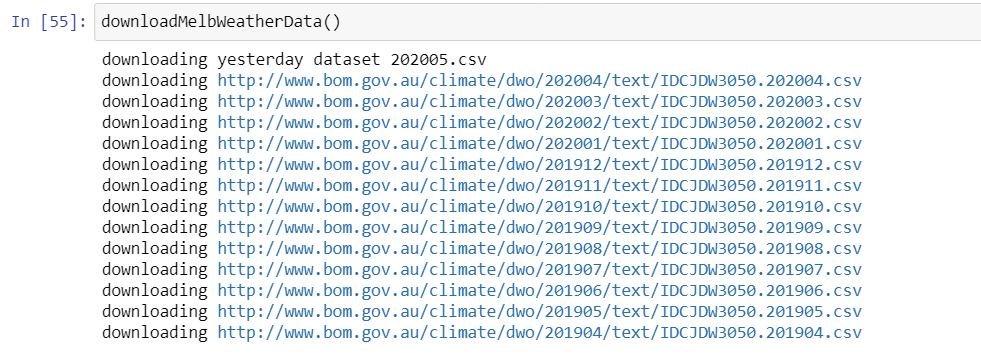
def downloadMelbWeatherData():
now = arrow.now()
n = now.format("YYYYMM")
print("downloading yesterday dataset "+n+".csv")
url = "http://www.bom.gov.au/climate/dwo/"+n+"/text/IDCJDW3050."+n+".csv"
os.system("wget -O {0} {1}".format(n+".csv", url))
uploadFileToBukect(n+'.csv')
for i in range(14):
m = now.shift(months=-i).format("YYYYMM")
url = "http://www.bom.gov.au/climate/dwo/"+m+"/text/IDCJDW3050."+m+".csv"
if isFileExistInBukect(m+".csv") == False:
print("downloading "+url)
os.system("wget -O {0} {1}".format(m+".csv", url))
uploadFileToBukect(m+'.csv')
os.system("rm {0} {1}".format(m+".csv"))
def combineDataset():
fs = gcsfs.GCSFileSystem(project='prediction-melb',token=json.load(open('prediction-melb-8c16f470aeda.json')))
boms = fs.ls('bomdata')
with open("all.csv", "w") as f2:
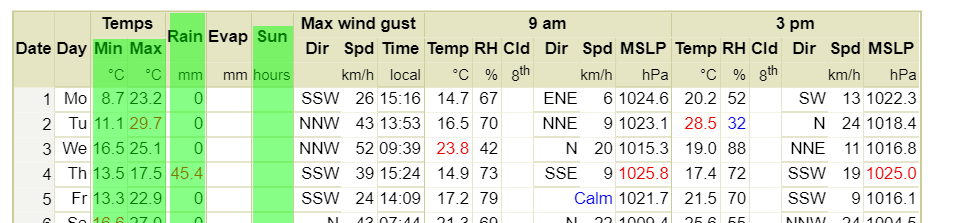
f2.write('"Non","Date","MiniTemp","MaxTemp","Rainfall","Evaporation (mm)","Sunshine","Direction of maximum wind gust ","Speed of maximum wind gust (km/h)","Time of maximum wind gust","9am Temperature (ḞC)","9am relative humidity (%)","9am cloud amount (oktas)","9am wind direction","9am wind speed (km/h)","9am MSL pressure (hPa)","3pm Temperature (ḞC)","3pm relative humidity (%)","3pm cloud amount (oktas)","3pm wind direction","3pm wind speed (km/h)","3pm MSL pressure (hPa)"\n')
for bom in boms:
lineNum = 0
with fs.open(bom) as f:
lines = f.readlines()
for line in lines:
lineNum = lineNum+1;
if lineNum > 9:
f2.write(str(line).replace("b'","").replace("\\r\\n'","\n"))
f2.write("\n")
lineNum = 0
def convertTTData(array,inputDayNum):
x = []
y = []
for i in range(len(array) - inputDayNum - 1):
x.append(array[i:inputDayNum+i])
y.append(array[inputDayNum+i])
return np.array(x).reshape(-1,inputDayNum),np.array(y)
def getLatetX(array,inputDayNum):
return np.array(array[len(array)-inputDayNum:])
def predict(array,inputDayNum):
x,y = convertTTData(array,inputDayNum)
px = getLatetX(array,inputDayNum)
regressor = LinearRegression()
regressor.fit(x, y)
py = regressor.predict([px])
return py[0]
def predictAndPushData():
downloadMelbWeatherData()
combineDataset()
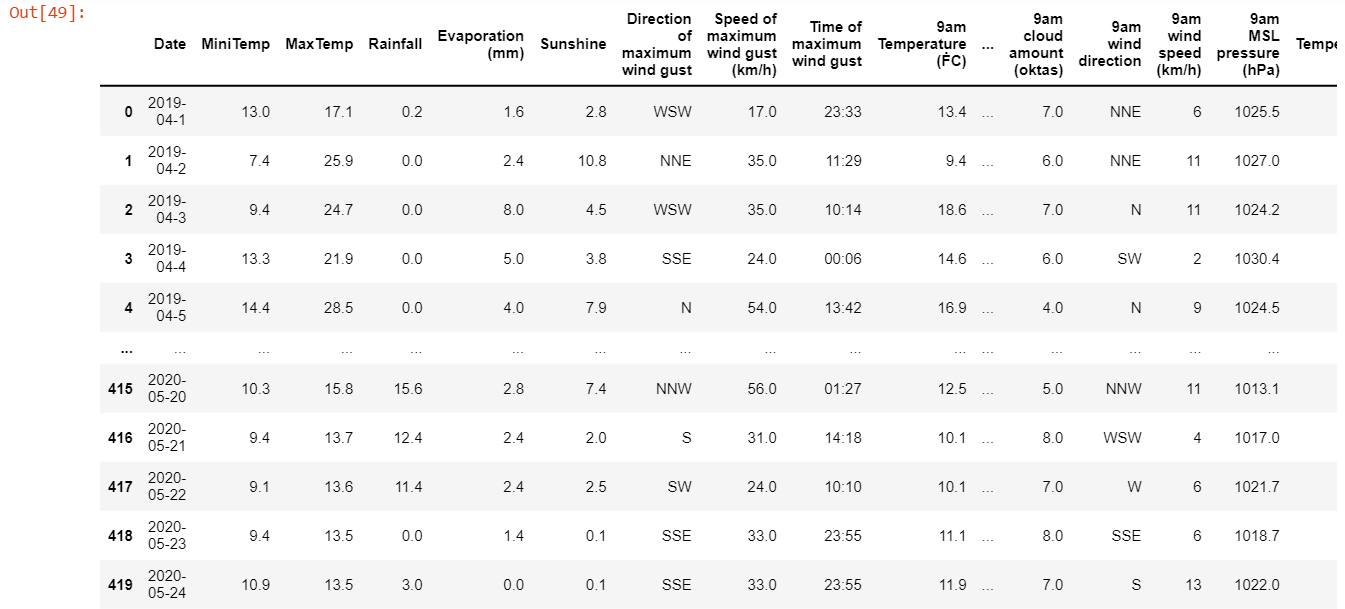
df = pd.read_csv("all.csv")
del df["Non"]
df = df.fillna(method='ffill')
df
now = arrow.now()
inputDayNum = 15
doc_ref = db.collection(u'predicted').document(now.format("YYYYMMDD"))
doc_ref.set({
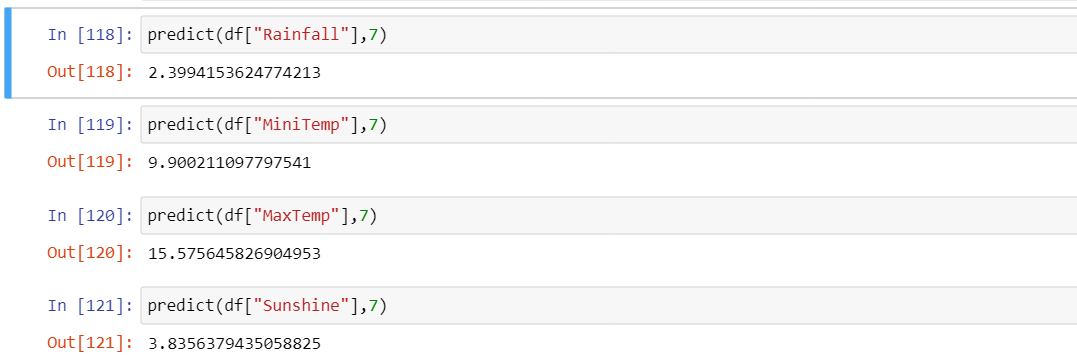
u'Rainfall': predict(df["Rainfall"],inputDayNum),
u'MiniTemp': predict(df["MiniTemp"],inputDayNum),
u'MaxTemp': predict(df["MaxTemp"],inputDayNum),
u'Sunshine': predict(df["Sunshine"],inputDayNum),
})
schedule.every().day.at("00:30").do(predictAndPushData)
while 1:
schedule.run_pending()
time.sleep(60*5)
|